前言
Flash Attention对于大语言模型(LLM)的训练和推理来说,几乎是必备的组件,其带来的性能提升有目共睹。通常pip install flash-attn就能搞定。但当我们面对特定硬件(比如A800)或者需要最新版的功能时,从源码编译就成了绕不开的路。
在跳坑多次后(:,今天还是来记录一下在A800服务器上,从源码编译安装flash-attn的完整过程,以及其中遇到的一些“坑”和关键注意事项。
环境与背景
本地环境
- 服务器: 64 Cores CPU, 512G RAM
- GPU: NVIDIA A800 80G (PCIe)
- CUDA: 12.2
- PyTorch: 2.7.1+cu118
官方仓库的README文档
Requirements:
- CUDA toolkit or ROCm toolkit
- PyTorch 2.2 and above.
packagingPython package (pip install packaging)ninjaPython package (pip install ninja) *- Linux. Might work for Windows starting v2.3.2 (we’ve seen a few positive reports ) but Windows compilation still requires more testing. If you have ideas on how to set up prebuilt CUDA wheels for Windows, please reach out via Github issue.
* Make sure that
ninjais installed and that it works correctly (e.g.ninja --versionthenecho $?should return exit code 0). If not (sometimesninja --versionthenecho $?returns a nonzero exit code), uninstall then reinstallninja(pip uninstall -y ninja && pip install ninja). Withoutninja, compiling can take a very long time (2h) since it does not use multiple CPU cores. Withninjacompiling takes 3-5 minutes on a 64-core machine using CUDA toolkit.To install:
1pip install flash-attn --no-build-isolationAlternatively you can compile from source:
1python setup.py installIf your machine has less than 96GB of RAM and lots of CPU cores,
ninjamight run too many parallel compilation jobs that could exhaust the amount of RAM. To limit the number of parallel compilation jobs, you can set the environment variableMAX_JOBS:
1MAX_JOBS=4 pip install flash-attn --no-build-isolation
小吐槽:官方文档提到“With ninja compiling takes 3-5 minutes on a 64-core machine using CUDA toolkit.”,不知道他们的设备该有多好,羡慕ing。。。
核心编译步骤
升级基础构建工具
在开始任何编译工作前,一个良好且最新的构建环境能避免掉80%的玄学问题。所以,确保pip,wheel和setuptools都是最新的。
| |
旧的setuptools可能会在解析构建脚本时格外的慢,不要问我怎么知道的。。。
安装并验证ninja
官方文档
也强调了ninja的重要性。没有它,编译过程会退化成单线程,耗时可能从几分钟飙升到几小时。哦不,几十分钟变成几百分钟也不是不可能。(官方仓库issue里面的真人真事
安装 Ninja
1pip install ninja验证 Ninja
官方文档提到的验证方法是运行
ninja --version然后echo $?查看退出码是否为 0。 我个人更推荐一个更直观的方法:在开始编译后,立刻新开一个终端,执行htop。如果你看到 CPU 列表里几十个cicc或者nvcc进程在同时运行,把 CPU 核心吃满,那ninja就肯定在正常工作了。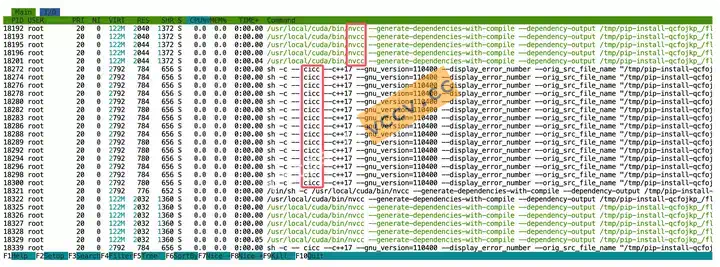
如果发现
ninja工作不正常,最直接的办法是彻底重装:pip uninstall -y ninja && pip install ninja。
配置关键环境变量
这是整个编译过程的灵魂,直接决定了编译能否成功以及效率如何。
FLASH_ATTN_CUDA_ARCHS:指定 GPU 计算能力这个环境变量告诉编译器,我们只为特定架构的 GPU 生成代码。A100 和 A800 的 Compute Capability 都是
8.0,因此我们设置为 “80”。如果不指定,它会尝试编译所有支持的架构,很浪费时间。- 查询地址: NVIDIA CUDA GPUs
在终端中设置:
1export FLASH_ATTN_CUDA_ARCHS="80"MAX_JOBS:设置并行编译任务数这个变量控制
ninja并行编译时使用的 CPU 核心数。理论上越多越快,但代价是内存消耗剧增。需要根据机器的 CPU 核心数和内存大小权衡。- 我的实践: 在 64 核 CPU、512GB 内存的机器上,我大胆地设置为
MAX_JOBS=64。 - 性能表现:
htop显示 64 核全满,编译峰值内存占用超过 300GB,耗时约 10-15 分钟。一个有趣的观察是,当htop中看到内存占用开始显著回落时,说明编译已接近尾声。 - 建议: 如果你的内存没那么充裕,可以从 CPU 核心数的一半开始尝试,例如
MAX_JOBS=32。
- 我的实践: 在 64 核 CPU、512GB 内存的机器上,我大胆地设置为
最终执行安装
万事俱备,只欠东风。整合所有环境变量,执行最终的安装命令。
| |
这里必须加上--no-build-isolation参数。它的作用是告诉pip在当前 shell 环境中直接构建,而不是创建一个隔离的虚拟环境。这样,我们刚刚export的那些环境变量才能被构建进程正确读取。
一些“小”坑(Troubleshooting)
问题一:编译报错
g++: fatal error: Killed signal terminated program cc1plus- 原因:这 99% 是内存不足(OOM Killer 发威了)。
cc1plus是 C++ 编译器进程,MAX_JOBS设置得太高,并行进程过多,瞬间就把内存吃完了。 - 解决:调低
MAX_JOBS的值,比如从 64 降到 32 或者 16 再试。
- 原因:这 99% 是内存不足(OOM Killer 发威了)。
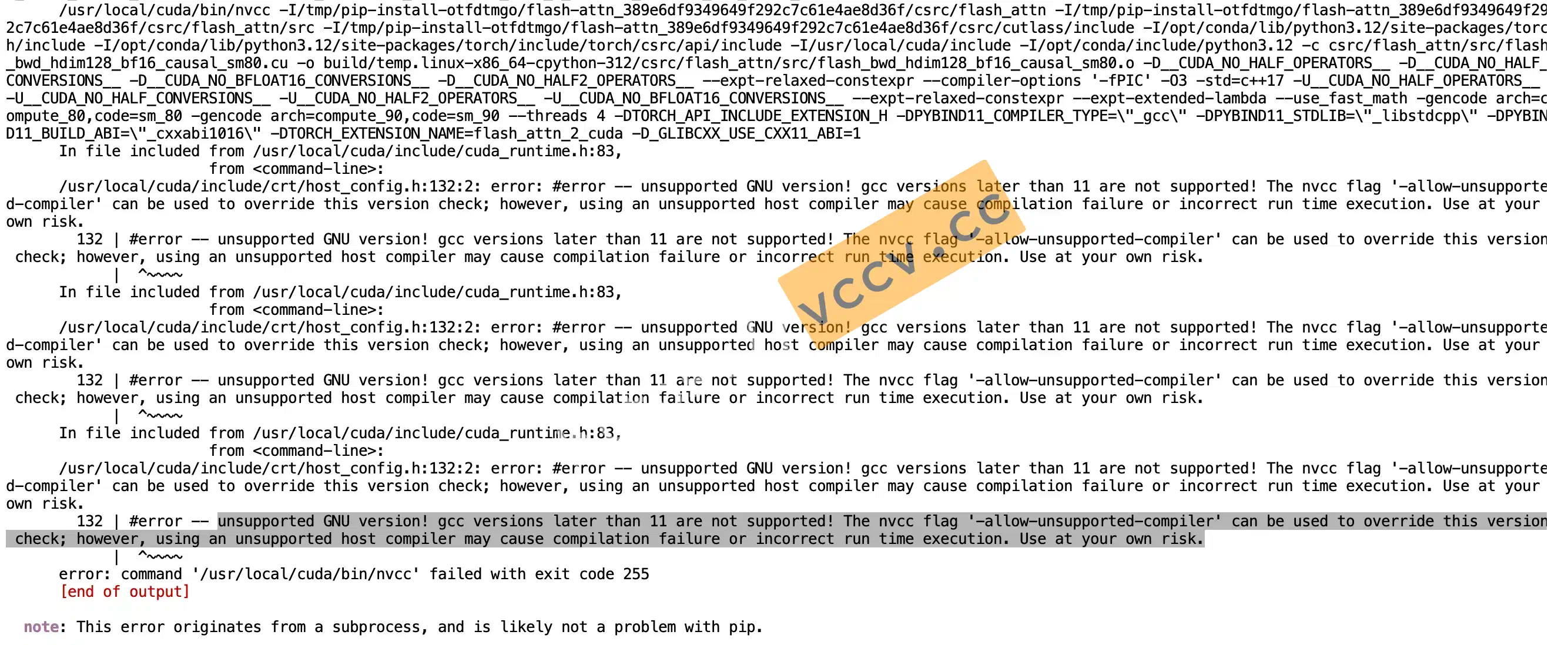
问题二:提示GNU版本太高
原因:截止发文时,编译要求
gcc-11和g++-11。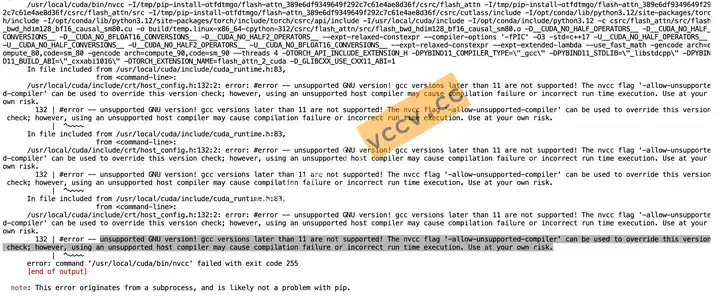
解决:
1 2 3 4 5 6 7 8 9# 以Ubuntu22.04为例 # 安装gcc-11 apt install gcc-11 g++-11 # 查看路径 which gcc-11 which g++-11 # 设置环境变量 export CC=/usr/bin/gcc-11 export CXX=/usr/bin/g++-11
问题三:编译时间长得离谱
- 原因:
ninja没有正常工作,编译退化成了单线程模式。 - 解决:按上文的方法验证
ninja。检查是否安装,或者重装ninja。
- 原因:
问题四:各种 CUDA 相关的编译错误
- 原因:大概率是
FLASH_ATTN_CUDA_ARCHS没设对,或者 PyTorch 版本与 CUDA Toolkit 版本不兼容。 - 解决:再次确认你的 GPU 型号和对应的计算能力。检查
nvidia-smi和nvcc --version的输出,确保环境一致。
- 原因:大概率是
备选方案
如果源码编译实在折腾不下去,或者你只是想快速用上一个稳定版,可以考虑:
- pip 安装预编译包:
pip仓库有时会提供针对主流环境的预编译包(wheels)。直接pip install flash-attn有时就能成功,但版本不一定最新,且不保证支持最新硬件。 - conda 安装:
conda渠道也可能提供预编译好的flash-attn,值得一试,运行conda install flash-attn -c conda-forge即可。